Deep GUIs

Introduction
As a mechanical engineer who transitioned into software, I’ve always been intrigued by the way stuff breaks down with bits. Friction wears things down, inertia keeps things going and passive stability maintains balance. Software, however, is unforgiving and brittle.
It’s pretty clear that this is going to change with LLMs. Some even say that language is becoming the new UI. It’s a compelling idea, but until we all have neuralink implants or AIs completely take over work, visual computing will always have an integral role to play in efficiently cramming piles of data into our brains.
This brings me to an intriguing aspect of generative AI that I haven’t heard much about since the release of Stable Diffusion (SD) and ChatGPT: generative GUIs. To clarify, I am not referring to LLMs creating frontend code that is then compiled into a website - a process that, while impressive, still carries the characteristic brittleness of software. Instead, I’m thinking about GUIs that are generated and customized in real-time, responding dynamically to user inputs of various kinds (not just text).
Subtle signs of this transition are already present. Several AI products are chipping away at traditional graphical workflows, integrating language as a central component:

These, however, are focused on specific use cases. Also, most of the ways the user interacts with the computer, inside or outside the app, is still bounded to GUIs designed by developers. Generative GUIs, on the other hand, would be entirely generated on the fly.
Below are some diagrams that clarify how this would differ from other similar approaches. The wider the block, the more applications it covers at that stack level, and the taller it is, the more it chips away at traditional software for a given application. ChatGPT would fit at the top-left corner of the diagram: it can be used for a wide variety of applications at the business layer, but it’s still limited to text outputs so it does not cover much of the presentation layer. Also, it requires some rendering code to be written to display the text properly, hence the bridge to the display layer. Something like Midjourney, would fit at the top-right corner: it covers a small set of applications (image generation and editing), but it does it end-to-end through the business and presentation layers. GUIs generated with LLMs and subsequently rendered are a bit of a mix. Generative GUIs however, would cover most of the stack: wide variety of applications, end-to-end.




As you can see, I’m using the world GUI very loosely here. In some sense it would be more accurate to talk about generative apps since the diagrams incorporate the business layer, but this term is too ambitious for this tiny project.
Toy example
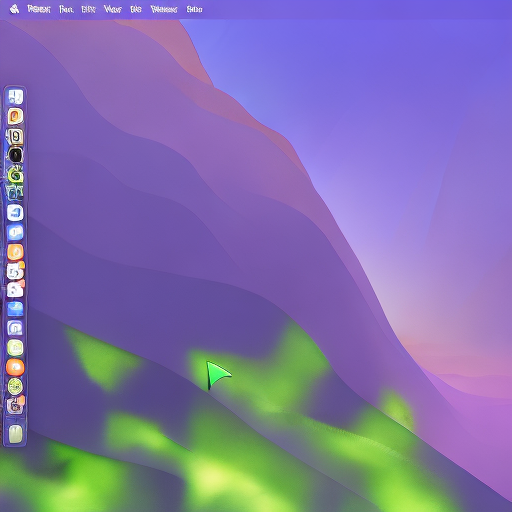
Building something like this is pretty massive. Big and ambitious companies only very recently managed to get LLMs to work sufficiently well, and visual data is at a much lower level of abstraction than text: modelling semantics at that level in order for it to do something useful is much harder. So, I decided to start with a toy example: mimicking my Mac’s desktop and mouse. This was hacked in a night (+ some training iterations), so it’s not perfect and rather simple. But, I think it manages to get the point across.
I capture my mouse’s x and y coordinates, I bin them to a 20x20 grid, format them as text, pass them to Stable Diffusion and train a ControlNet to generate the correct mouse position on my desktop:
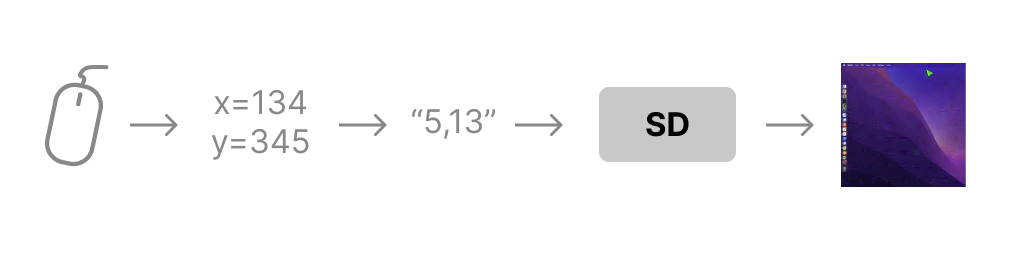
It took a couple of iterations to get it to work (binning, coordinate formatting, curriculum learning), which I’ll cover below. Here is the resulting model at work, running on an A10 GPU, driven by my local machine’s mouse, in near-realtime:
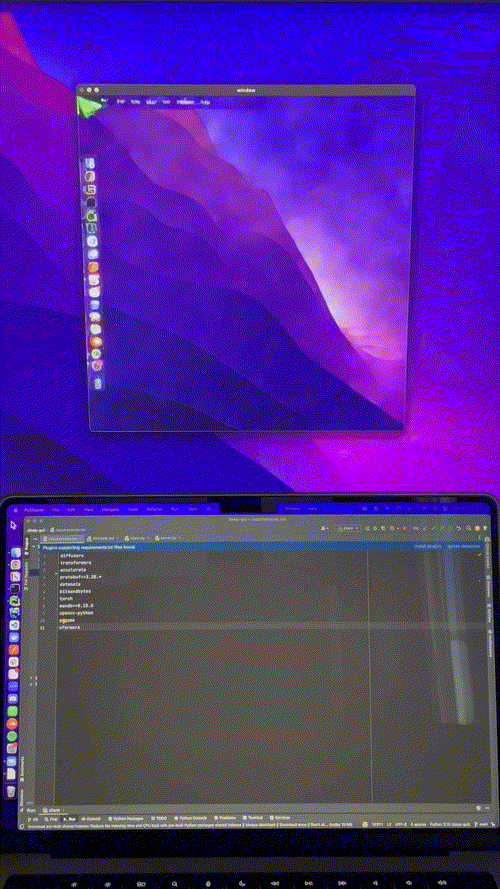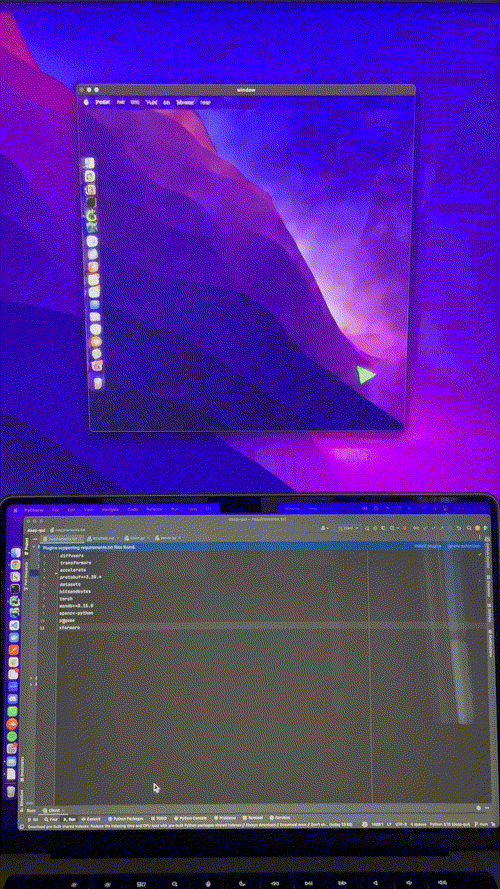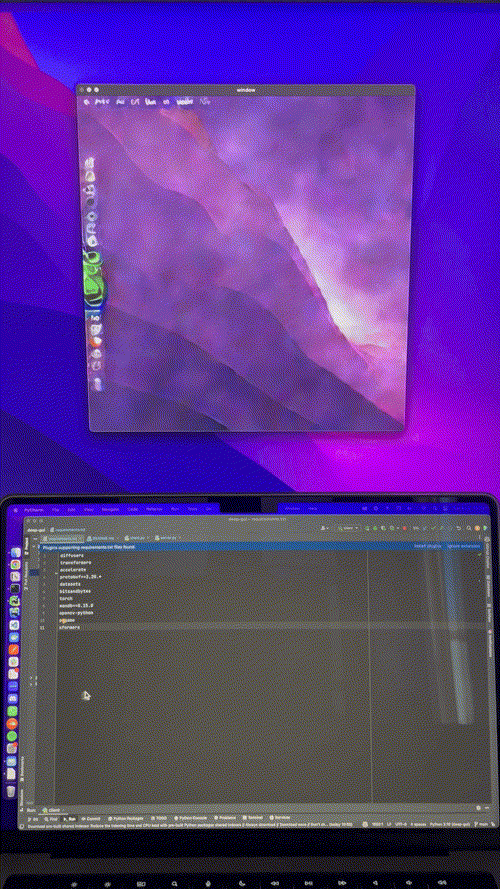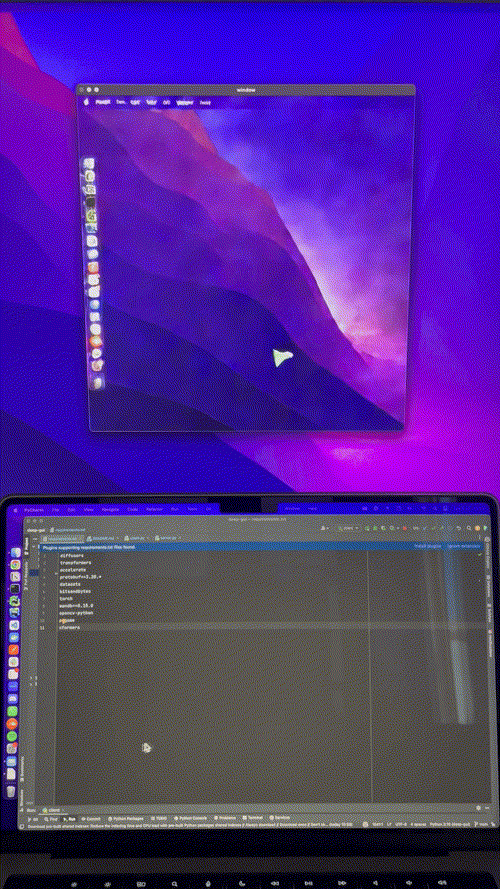
The inference script is currently pretty slow, so here is a sped up version of one session I recorded to drive the point home:
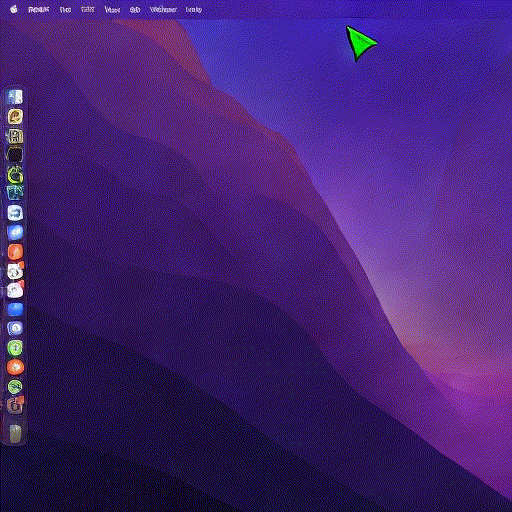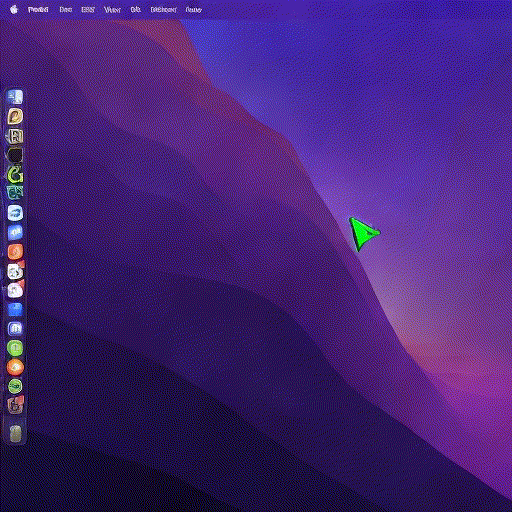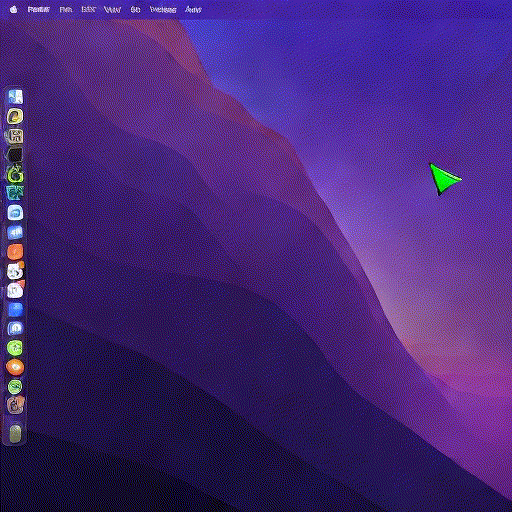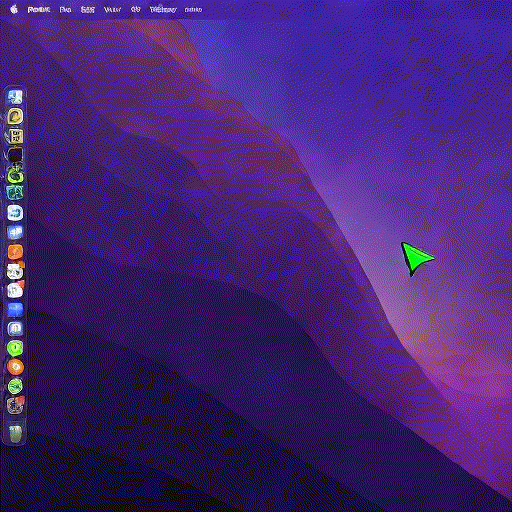
Think about it: a model taking in raw human input and rendering structured, semantically stable, and useful visual feedback. No lines of frontend code written, no rendering engine, and failure is soft (e.g. mouse with a slight offset).
Details
I’ll briefly go over the details of how I got this to work for anyone wanting to try it out (it’s really easy). In essence, this experiment is just a ControlNet trained on all 20x20 mouse positions on my desktop.
- I used img2img, with a screenshot of my desktop as the image prior, because I wanted to try training it to accommodate changing wallpapers zero-shot. Unfortunately I did not get the time to do it (leaving it for part 2). So, the image prior is pretty useless here.
- I first tried feeding the model with the raw mouse coordinates, but it didn’t work. I did not do a deep dive into the embedding space of CLIP, but it’s probably because CLIP can’t dissociate with such fine-grained coordinates.
- I then binned the coordinates to a 20x20 grid, which worked okay but not great.
- I then tried curriculum learning, starting with only a couple mouse positions and ramping up to the full 20x20 grid, which worked a lot better (or at least gave me some signal that the model was learning something).
- To get around the 20x20 grid limitation, I tried interpolating in embedding space, but it did not change much. I also tried using stuff like frame interpolation, but again it did not change much.
Here are some pretty funny phases in the training process (the image prior is always the original screenshot of my desktop):
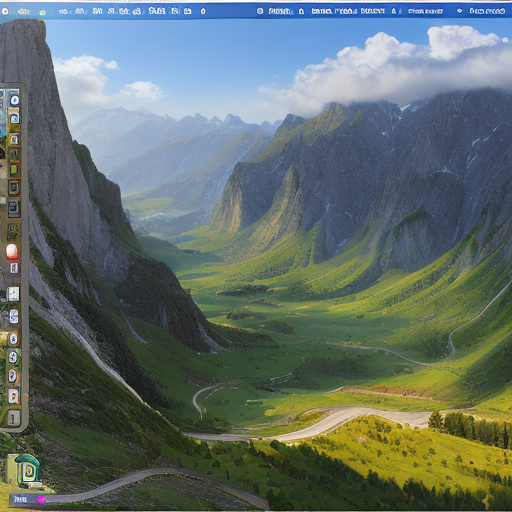


Looking forward
Of course, this toy example is pretty useless as is. The rendering is limited to the mouse, and even if it could render windows, it’s ultimately not connected to any filesystem or application. Also, the supervised training procedure makes it hard to scale to more complex tasks.
But, this experiment is complementary to backend-GPT, which got some attention a few months ago. Instead of using CLIP as the embedder, some bigger LLM and memory module could be fused with SD to be used as the backend, along with other modality intakes such as the mouse. With a better backend, here are a couple of ideas of more useful things that could be done for part 2:
- Clicking and opening windows
- Swapping wallpaper and app icons
- Rendering super simple apps
To make these ideas work, some smarter self-supervised training procedure should be devised, which would probably be the hardest part to crack. Also, the speed of inference would need to be dramatically improved for it to be truly real-time.
If you’re interested in any of this or have ideas, please reach out! In any case stay tuned for part 2!
Related
Here are papers and articles that I thought about while working on this project:
- World Models by David Ha and Jürgen Schmidhuber.
- GAIA-1 by Wayve.
- Learning to Simulate Dynamic Environments with GameGAN by SW Kim et al.
- Building a Virtual Machine inside ChatGPT by Jonas Degrave.
- backend-GPT by @DYtweetshere , @evanon0ping , and @theappletucker .
- Make-A-Video by Uriel Singer et al.
Reactions
This kind of stuff makes you question the nature of reality itself!
— Scott Stevenson (@scottastevenson) July 14, 2023
Eg. Could the top visible layer of our conscious experience be the primary thing that’s being “generated”?
If this generative desktop interface let you explore an underlying OS and file system, is that like…
Inference is eating software https://t.co/pY8sKeWdSW
— Mike Knoop (@mikeknoop) July 14, 2023
This is very cool and hints at the future of technology https://t.co/vjVuscMbYB
— Hypron (@_Hypron) July 16, 2023
Update: January 19th 2025
As a testament to the speed of AI progress, the predictions made in this blog about generative apps became a reality 6 months later, in 2024, with a focus on video games. To cite a few: Genie, Genie 2, DIAMOND and GameNGen.